Lab 4: Funcionalidade Datapool
O Datapool é uma funcionalidade da BotCity que permite o processamento de um conjunto de itens em larga escala. Com ele conseguimos ter controle e granularidade sobre os itens, acompanhando seu progresso, status, tempo de execução por item, etc.
O Datapool pode ser configurado com política de consumo, número tentativas de reprocessamento um item que falhou, parar o consumo da fila em caso de muitas falhas consecutivas e gatilhos para criar tarefas automaticamente.
Com o Datapool, abrimos a possibilidade aumentar a eficiência e reduzir o tempo de espera desses itens em fila paralelizando execuções. Ou seja, os itens de uma única fila podem ser distribuídos entre várias tarefas da mesma automação.
Criar um Datapool
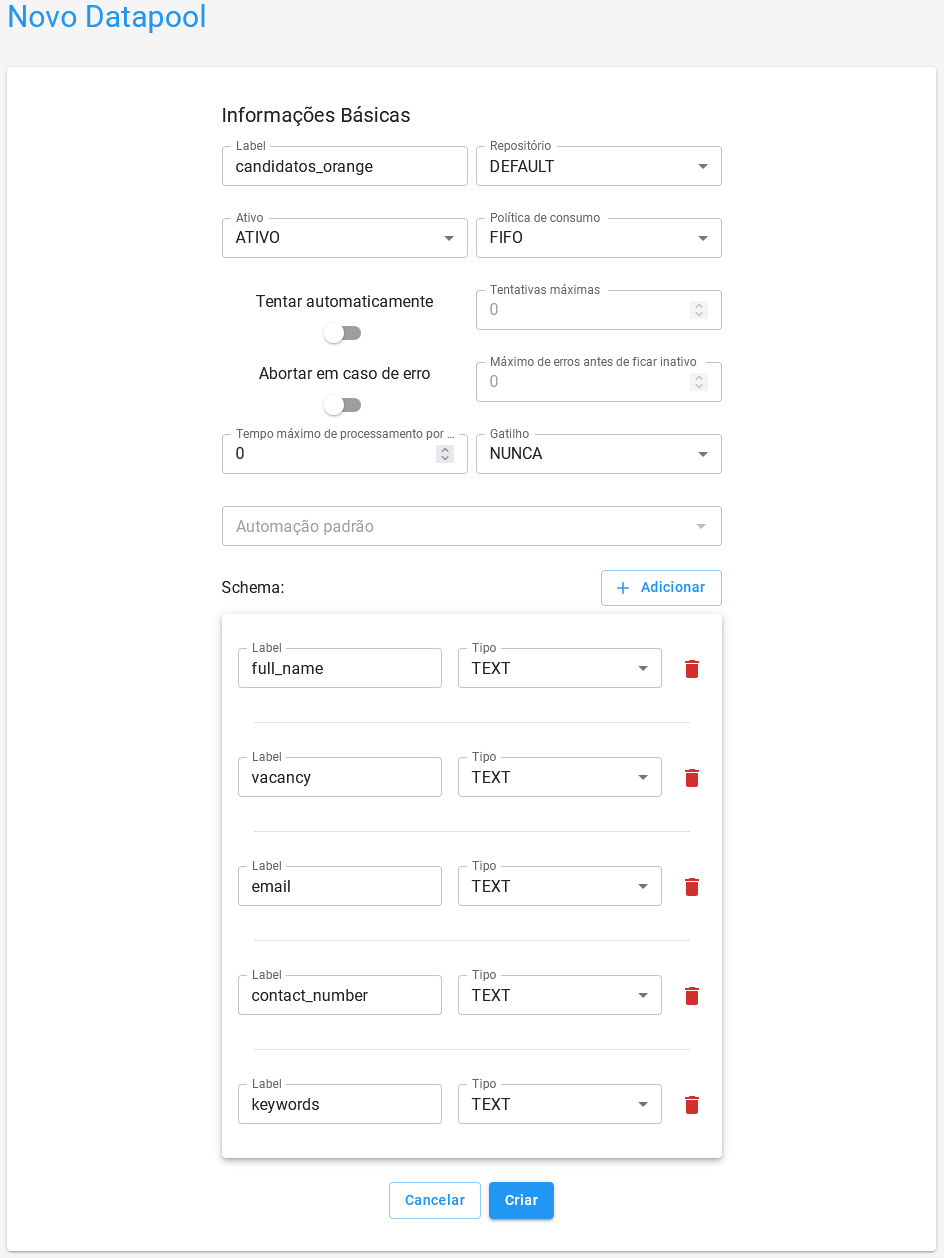
Para esse projeto, crie um Datapool navegando no menu lateral do Orquestrador BotCity Maestro até Datapool, clique em + Novo Datapool
e preencha os campos do formulário:
- Label: O identificador único que será utilizado para acessar o Datapool.
- Repositório: O repositório onde o Datapool será armazenado.
- + Adicionar: O schema do Datapool.
- Label: O identificador único para a coluna.
- Tipo: O tipo de dado que a coluna armazenará.
Para esse workshop adicione 5 colunas no schema, todas com o tipo TEXT:
full_namevacancyemailcontact_numberkeywords
O formulário ficará semelhante a essa imagem:
Nota
Para entender cada um dos campos, veja a documentação do Datapool.
Com tudo preenchido, clique em Criar.
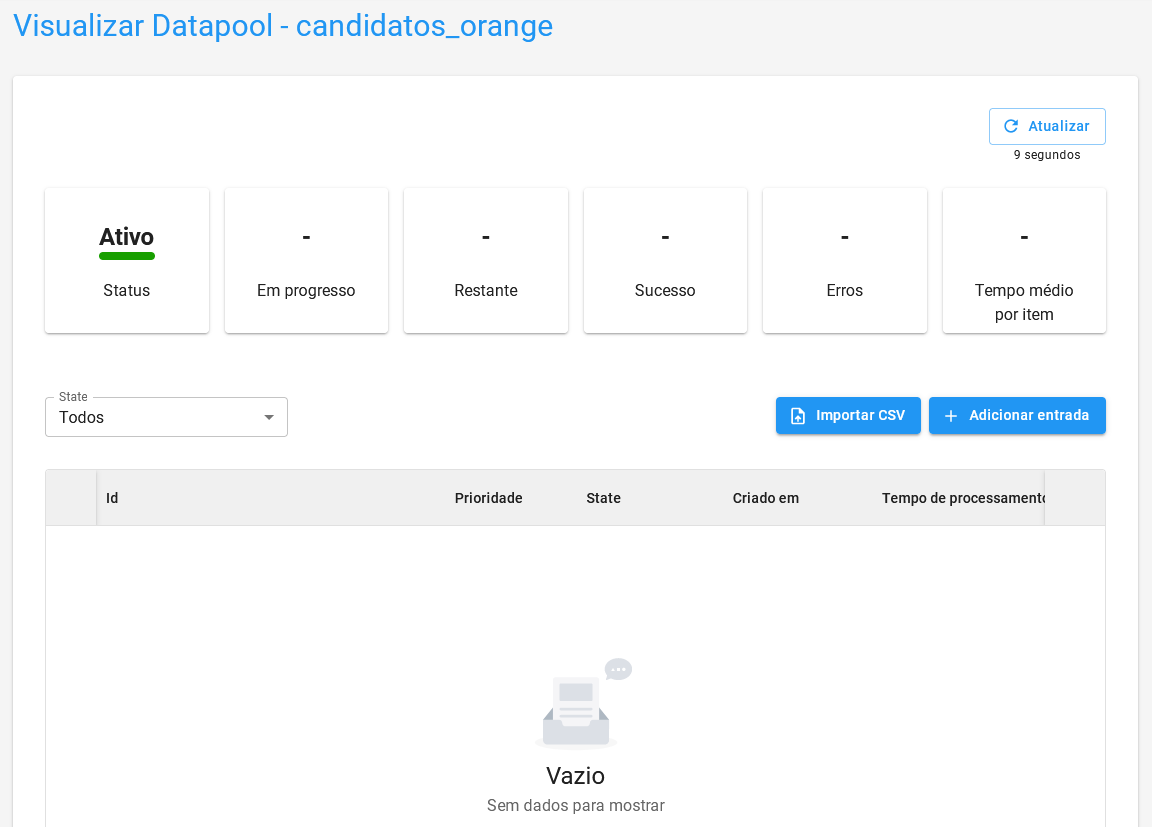
Após, encontre-o na lista de Datapools e clique para verificar os detalhes. A tela será semelhante a essa:
Adicionar itens ao Datapool
Você pode adicionar itens ao Datapool de diversas formas, sendo as mais comuns:
Adicionar manualmente
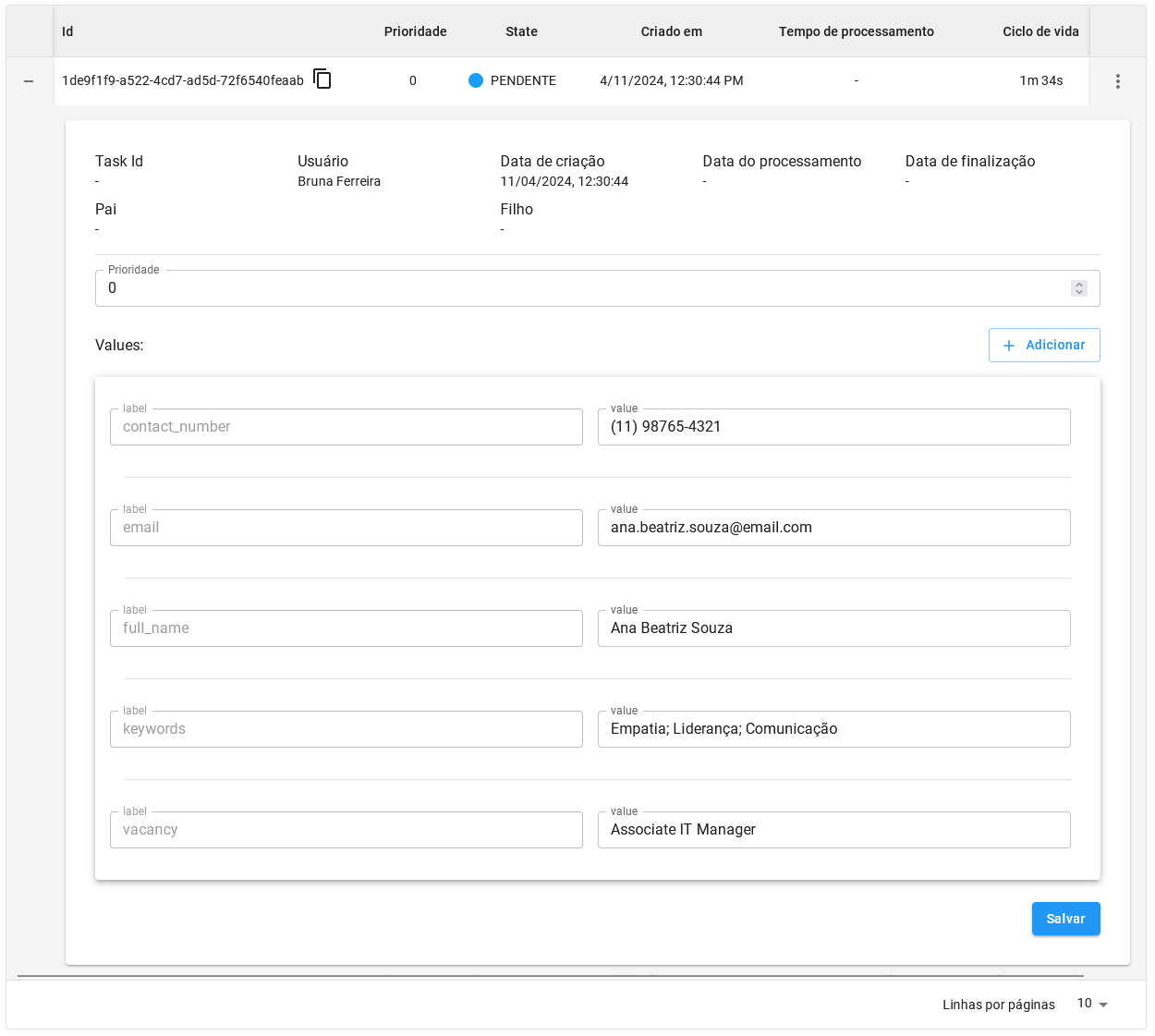
Para adicionar manualmente, clique em + Adicionar entrada.
O primeiro campo será a prioridade do item, que pode ser um número de 0 a 10. Quanto maior o número, maior a prioridade do item.
Preencha os cinco campos definidos no schema com os valores que você deseja que sejam processados no cadastro.
Você também pode adicionar mais campos para um item unico clicando em + Adicionar, caso necessite de informações opcionais para esse item.
Exemplo:
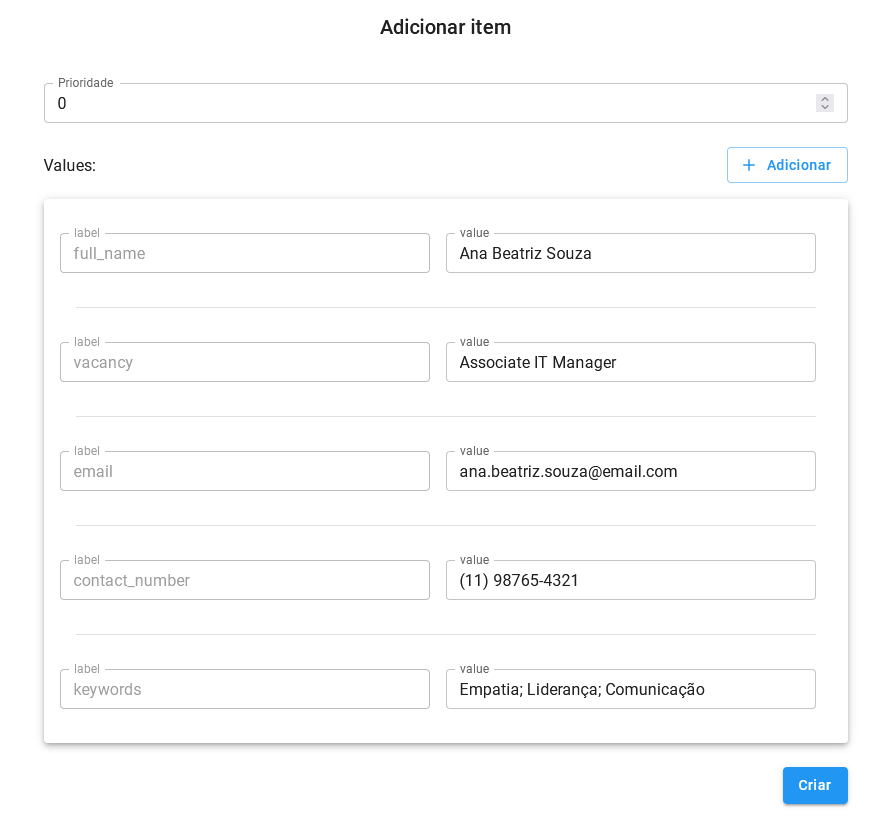
Com tudo preenchido, clique em Criar, o item ficará semelhante a essa imagem:
Nota
Adicionar itens dessa forma é útil para testes ou quando você precisa adicionar itens pontuais. No entanto, não é a forma mais eficiente para adicionar muitos itens de uma só vez, podendo ser demorado e propenso a erros de digitação.
Adicionar em lote
Uma forma mais eficiente de adicionar itens através um arquivo .csv.
Para adicionar itens dessa forma, clique em Importar CSV e arraste o arquivo ou clique para selecionar e navegue até ele.
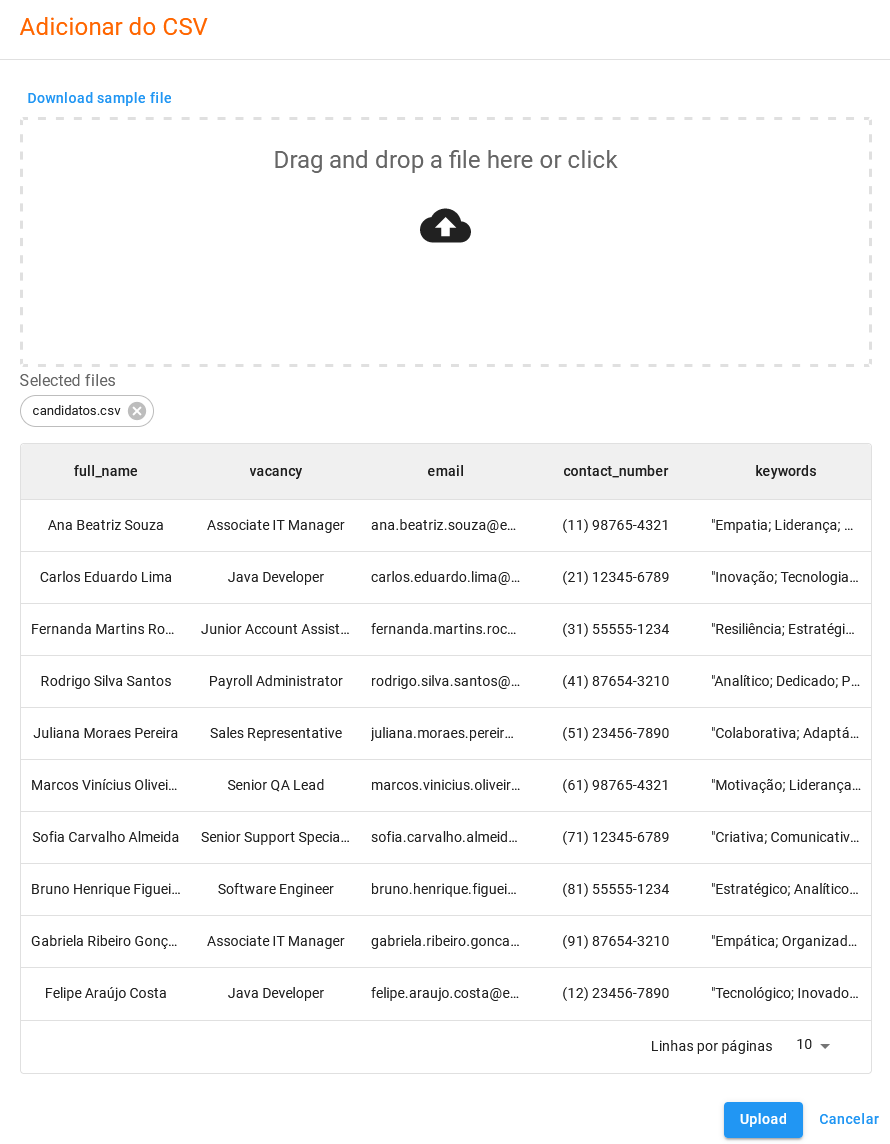
Desta forma, a primeira linha do .csv é o cabeçalho que define as colunas e as demais linhas se tornam os itens.
Nota
O arquivo .csv deve seguir o padrão do schema do Datapool, ou seja, as colunas devem ter os mesmos nomes e tipos definidos.
O arquivo utilizado neste exemplo está disponível para download clicando nesse link.
Clique no botão Upload para adicionar os itens ao Datapool.
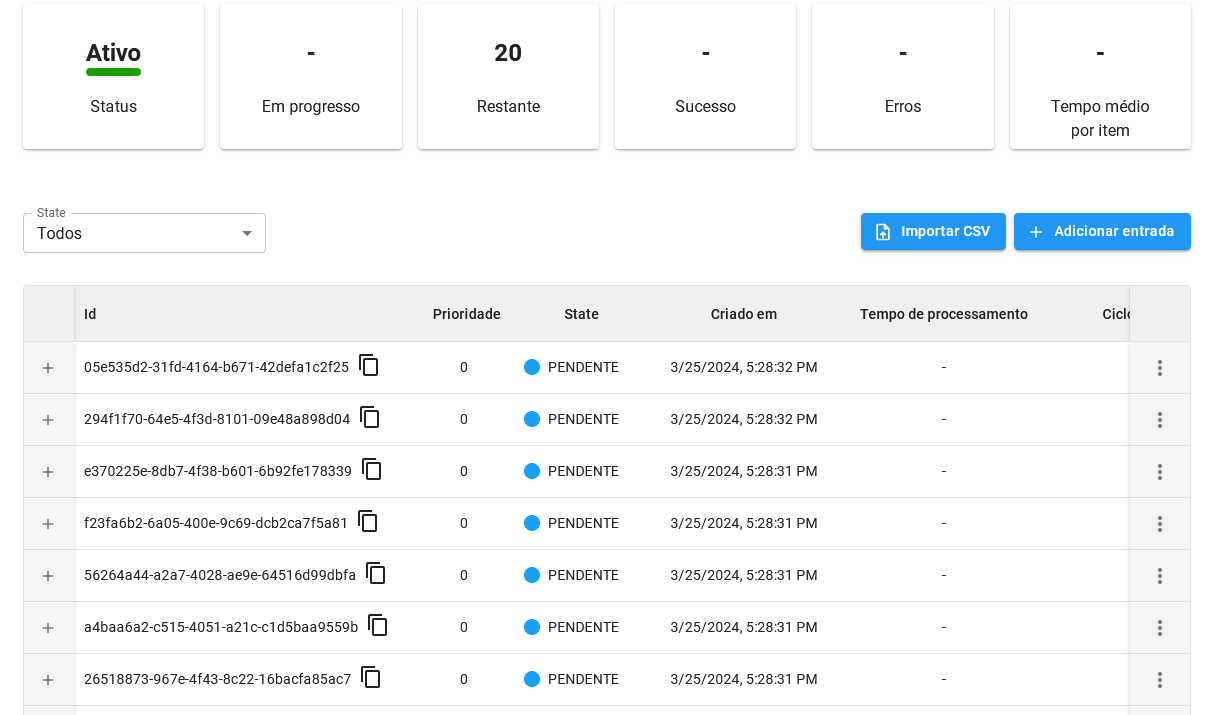
Note que os itens adicionados possuem o status PENDENTE, isso significa que estão aguardando processamento.
Nota
Para entender mais sobre os status durante o processo, veja a documentação do Datapool.
Integração no código
Com os itens prontos para serem processados, verifique o label do Datapool no código da automação, ele deve ser o mesmo que você acabou de criar.
Procure pelo método get_datapool e verifique se o label está correto. O código deve ser semelhante a este:
# Definir o datapool
datapool = maestro.get_datapool(label="candidatos_orange")